The following post is a short summary of a paper I worked on. Read the full paper here.
Our paper got accepted at EMNLP 2023 Demo Track!
In the realm of machine learning, and especially NLP, the creation of high-quality labeled data has been a significant bottleneck. We therefore present Fabricator, a toolkit designed to harness the power of LLMs for generating vast, labeled datasets. This approach not only promises to save time and resources but also opens new avenues for research and application in machine learning.
How It Works
By prompting LLMs to produce data for specific tasks, Fabricator efficiently creates training material for downstream NLP models. Imagine generating hundreds of movie reviews with varying sentiments at the push of a button.
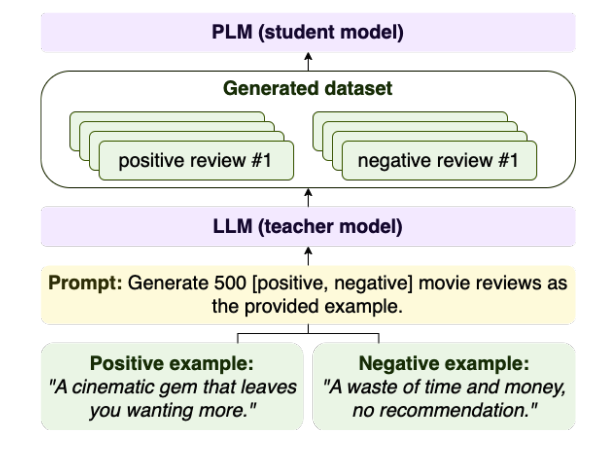
The process of learning via dataset generation. A teacher model (LLM) is prompted to generate 500 movie reviews for each sentiment (positive, negative). A smaller student PLM is trained on the generated dataset.
Versatility and Integration
Fabricator supports a wide array of NLP tasks and offering seamless integration with well-known libraries. Whether you’re working on text classification, entity recognition, or any other NLP challenge, Fabricator helps you generate the data you need.
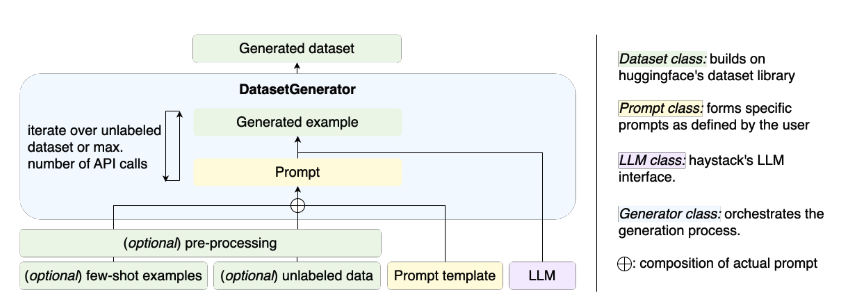
With FABRICATOR, the generation process involves a prompt template that creates the final prompt using all provided arguments. The generator class creates training examples until the maximum number of prompt calls is reached, or the unlabeled dataset is fully annotated. Ultimately, the generator class produces a HuggingFace Dataset instance.
Empowering Research and Development
By providing a means to quickly generate and experiment with new datasets, Fabricator paves the way for innovative research and practical applications in NLP.
import os
from datasets import load_dataset
from haystack.nodes import PromptNode
from fabricator import DatasetGenerator, BasePrompt
dataset = load_dataset("processed_fewshot_imdb", split="train")
prompt = BasePrompt(
task_description="Generate a {} movie review.",
label_options=["positive", "negative"],
generate_data_for_column="text",
)
prompt_node = PromptNode (
model_name_or_path="gpt-3.5-turbo",
api_key= os.environ.get("OPENAI_API_KEY"),
max_length=100,
)
generator = DatasetGenerator(prompt_node)
generated_dataset = generator.generate(
prompt_template=prompt ,
fewshot_dataset=dataset,
fewshot_sampling_strategy="uniform ",
fewshot_examples_per_class=1,
fewshot_sampling_column="label",
)
generated_dataset.push_to_hub("generated-movie-reviews")
A script that uses FABRICATOR and generates additional movie reviews based on few-shot examples
Looking Ahead - As the toolkit evolves, it promises to expand its capabilities, supporting an even broader range of tasks and enhancing the NLP community’s ability to tackle complex problems with novel solutions.
For more details, refer to the original paper: Fabricator