Our paper got accepted at EMNLP 2024 at the CoNLL BabyLM Workshop!
Read the full paper here
AbstractThis paper explores the potential of recurrent neural networks (RNNs) and other subquadratic architectures as competitive alternatives to transformer-based models in low-resource language modeling scenarios.
We utilize HGRN2 (Qin et al., 2024), a recently proposed RNN-based architecture, and comparatively evaluate its effectiveness against transformer-based baselines and other subquadratic architectures (LSTM, xLSTM, Mamba). Our experimental results show that BABYHGRN, our HGRN2 language model, outperforms transformer-based models in both the 10M and 100M word tracks of the challenge, as measured by their performance on the BLiMP, EWoK, GLUE and BEAR benchmarks. Further, we show the positive impact of knowledge distillation. Our findings challenge the prevailing focus on transformer architectures and indicate the viability of RNN-based models, particularly in resource-constrained environments.
Chapter 1
What is BabyLM?

We published this paper as part of the BabyLM Challenge. Let’s begin by explaining what this challenge is all about.
The challenge is targeted towards researchers who are interested in pretraining and/or cognitive modeling and optimizing pretraining given limited data inspired by human development. The primary goal is to foster research around this topic with a secondary goal of democratizing pretraining and training practices - which are typically targeted towards large, resource-rich research and industry groups.
This is realized through a challenge, where a restricted amount of pre-training data is allowed. They are defined as strict-small and strict, where a model is only allowed to be trained with 10M and 100M tokens respectively. How often the model sees the data does not matter.
Submitted models are evaluated on three zero-shot benchmarks BLiMP, BLiMP-Supplement, and EWoK and fine-tuned+evaluated on a subset of the (Super)GLUE datasets.
Chapter 2
Subquadratic LMs as Alternatives to Transformers
One cool thing about the BabyLM Challenge is, that it is not necessarily about pushing the benchmark scores to their limits, but to explore alternative architectures, training strategies, learning paradigms and data augmentation techniques. This created a wide range of submissions and a lot of creative approaches and interesting findings. I can only recommend to checkout the proceedings of the workshop to get an overview of everything.
Link to Proceedings: BabyLM Workshop
One of the key motivations behind our work is to explore the potential of subquadratic architectures as competitive alternatives to transformer-based models in low-resource language modeling scenarios.
But why should we consider subquadratic models in the first place?
Transformer-based models have become the de facto standard for a wide range of NLP tasks due to their strong performance across various benchmarks. A big selling point of transformers, is their ability to process input sequences in parallel, which makes them highly efficient, scalable and therefore suitable for large-scale pretraining of Language Models. This overshadowed the, in comparison, sequential processing of RNNs, which are often seen as slow and computationally expensive.
If we had to write down the computationally complexity, it would look like this:
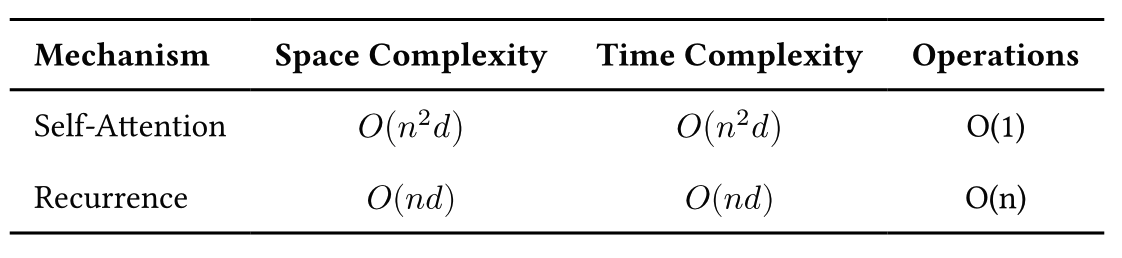
Doesn’t look too bad for RNNs in terms of complexity, right? The crucial point is the number of operations needed to process a sequence of length n, which is linear for RNNs. The high computational costs of Transformers are overcome through massive parallelization of the attention mechanism, which is key to their success. While a true RNN cannot overcome this bottleneck, several recent architectures have attempted to address this issue.
There is a wide variety of proposed new architectures that, at least to some extend, resemble RNNs. Following shows a non-exhaustive list of subquadratic architectures:
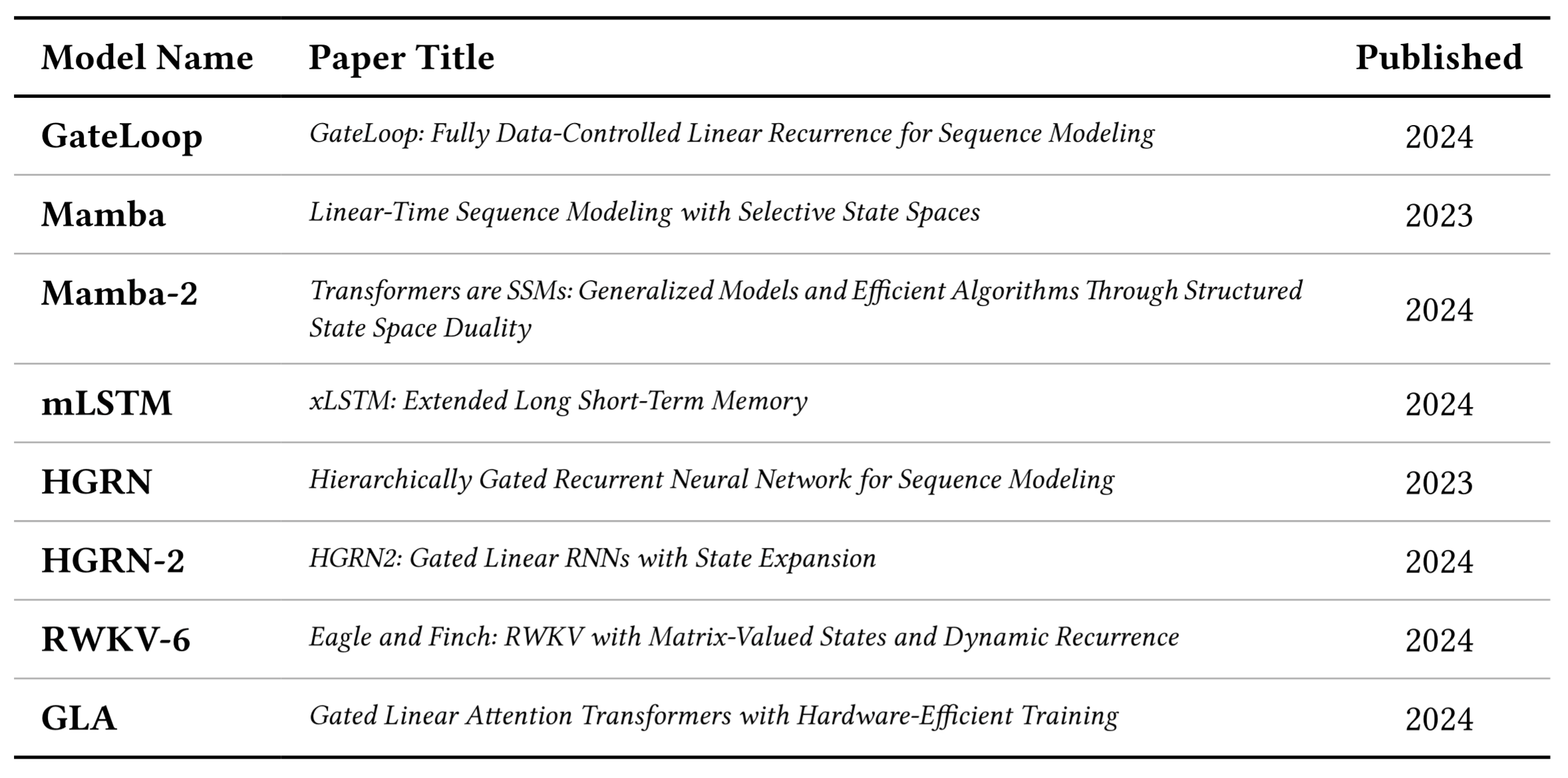
These architectures share a common goal of reducing the computational complexity of the model by introducing some kind of approximation or by reducing the number of operations needed to process the input sequence. This usually results in a trade-off between performance and computational efficiency. Ideally, a subquadratic model should be able to compete with transformer-based models in terms of performance, while being as efficient for training and more efficient for inference.
In a future post, we will dive deeper into how this is achieved through Linear Attention and all the other cool stuff that is going on in the field of subquadratic models.
So that is what we looked into. We utilized HGRN2, a recently proposed RNN-based architecture, and comparatively evaluated its effectiveness against transformer-based baselines and other subquadratic architectures like LSTM, xLSTM, and Mamba.
Chapter 3
Comparative Evaluation
For a fair comparison, we trained all models on the same data and used the same hyperparameters, except for the learning rate, which was tuned individually for each model. We therefore conducted a learning rate sweep to find the optimal learning rate for each model. Each model was trained on the strict-small track of the challenge for 5 epochs. After each epoch, we evaluated the model on the BabyLM benchmarks. Following table shows the results of our experiments:
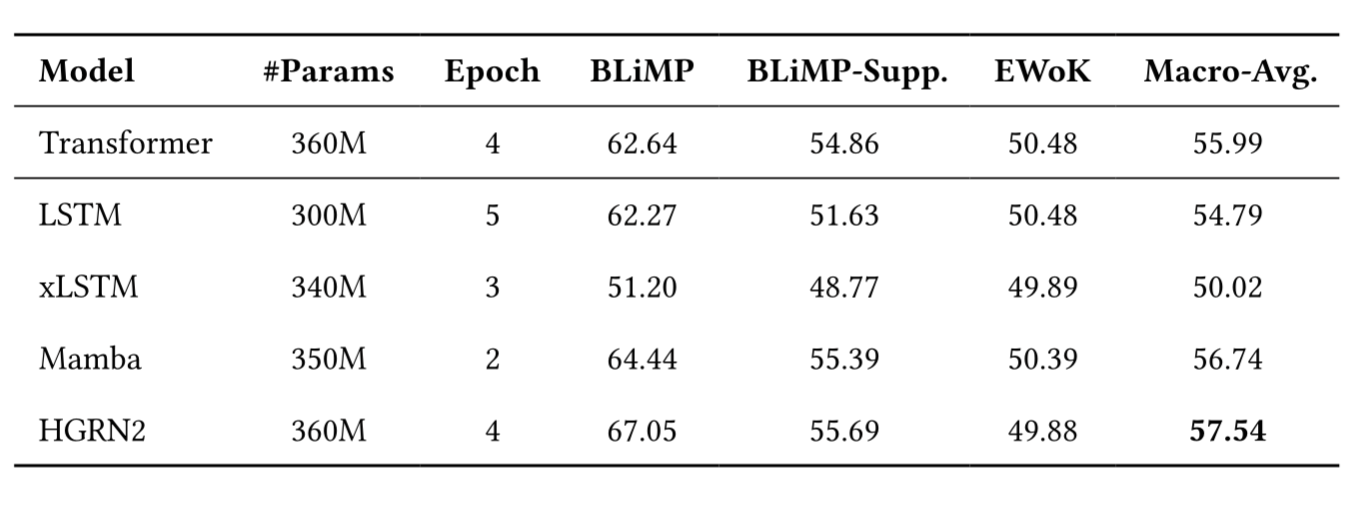
The evaluation revealed several interesting patterns across different model architectures. HGRN2 exhibited the strongest overall performance, followed closely by xLSTM and Mamba. Both models outperformed the transformer baseline, suggesting that these architectures offer distinct advantages in low-resource scenarios.
This makes the HGRN2 quite usefull for BabyLM and other low-resource scenarios, especially given the low computational costs of training and inference!
For our final submission, we wanted to pump those numbers up and decided to use knowledge distillation to further improve the performance of our model. We used one of the simpler setups for knowledge distillation, by training with Cross-Entropy loss and the teacher’s predictions as soft targets.
\[Loss_{KD} = Loss_{CE} + Loss_{KD}\]where \(Loss_{CE}\) is the Cross-Entropy loss and \(Loss_{KD}\) is the knowledge distillation loss.
\[Loss_{KD} = KL(\sigma(p_i), \sigma(q_i))\]where:
- \(z_t\) and \(z_s\) are the output logits of the teacher and student model respectively
- \(\sigma(z)\) is the softmax function applied to the logits \(z\)
Instead of the traditional approach of distilling from a larger to a smaller model, we used same-sized teacher and student models. Trained on the same dataset!
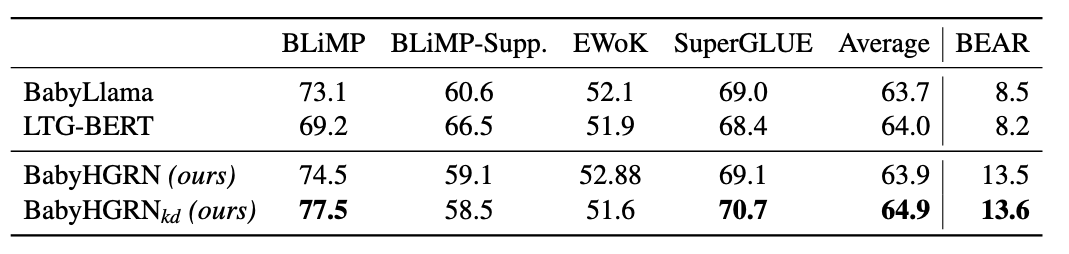
… Which actually worked out quite well! The knowledge distillation improved the overall performance of our model, which is quite impressive given the simplicity of the setup.
The organizers of the BabyLM Challenge set up this nice leaderboard, where you can see the performance of all submissions.
Its quite impressive to see how many different approaches were taken to tackle this challenge and how our really simple approach can compete with being on place 5 in the leaderboard.
For more details about our work, you can find the full paper here.
This, concludes our post. Here are more relevant links: