xLlaMA - A linearzed xLSTM language model
What is xLlaMA?
xLlaMA linearization of the SmolLM2-1.7B model with mLSTM as the token mixer backbone. The model is aligned with 3B token subset of the Fineweb dataset, which we trained with a modified MOHAWK training scheme.
Models
xLlaMA models come in different size, based on the SmolLM2 collection.
| Model | HF Model | Base Model |
|---|---|---|
| xLlama-190M | 🤗 xLlama-190M | 🤗 SmolLM2-135M |
| xLlama-450M | 🤗 xLlama-450M | 🤗 SmolLM2-360M |
| xLlama-1.9B | 🤗 xLlama-1.9B | 🤗 SmolLM2-1.7B |
Quickstart
Installation
For now the model requires a CUDA enabled GPU to run.
python -m pip install xlstm
python -m pip install mlstm_kernels
python -m pip install flash-attn --no-build-isolation
Text Generation
from transformers import AutoConfig, AutoModelForCausalLM, AutoTokenizer, pipeline
model_path = "PatrickHaller/xLlama-1.9B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
config = AutoConfig.from_pretrained(model_path, mode="inference")
model = AutoModelForCausalLM.from_pretrained(model_path, config=config)
pipe = pipeline('text-generation', model=model, tokenizer=tokenizer)
pipe("Once upon a time, there was a")
Evaluation
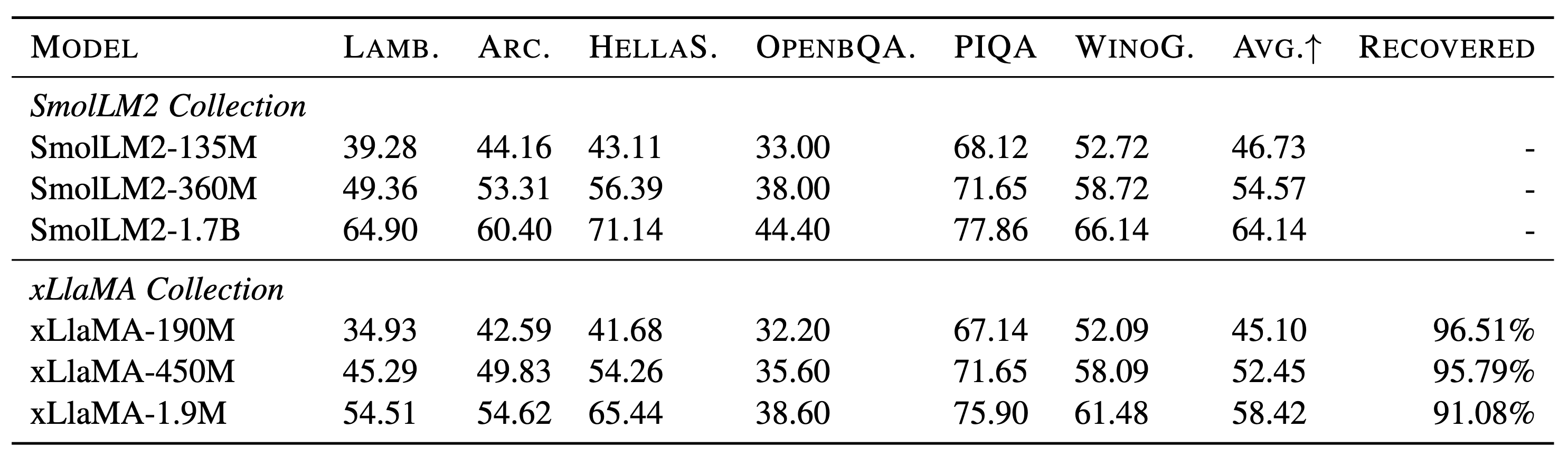
We evaluated each model against common LM benchmarks and also report the recvorage to the original teacher model.
License
Like the SmolLM family, this model is licensed under the Apache 2.0 license.